[Hadoop] Hadoop 개념 정리
Hadoop 기본 개념
- V1
- V2
- V3
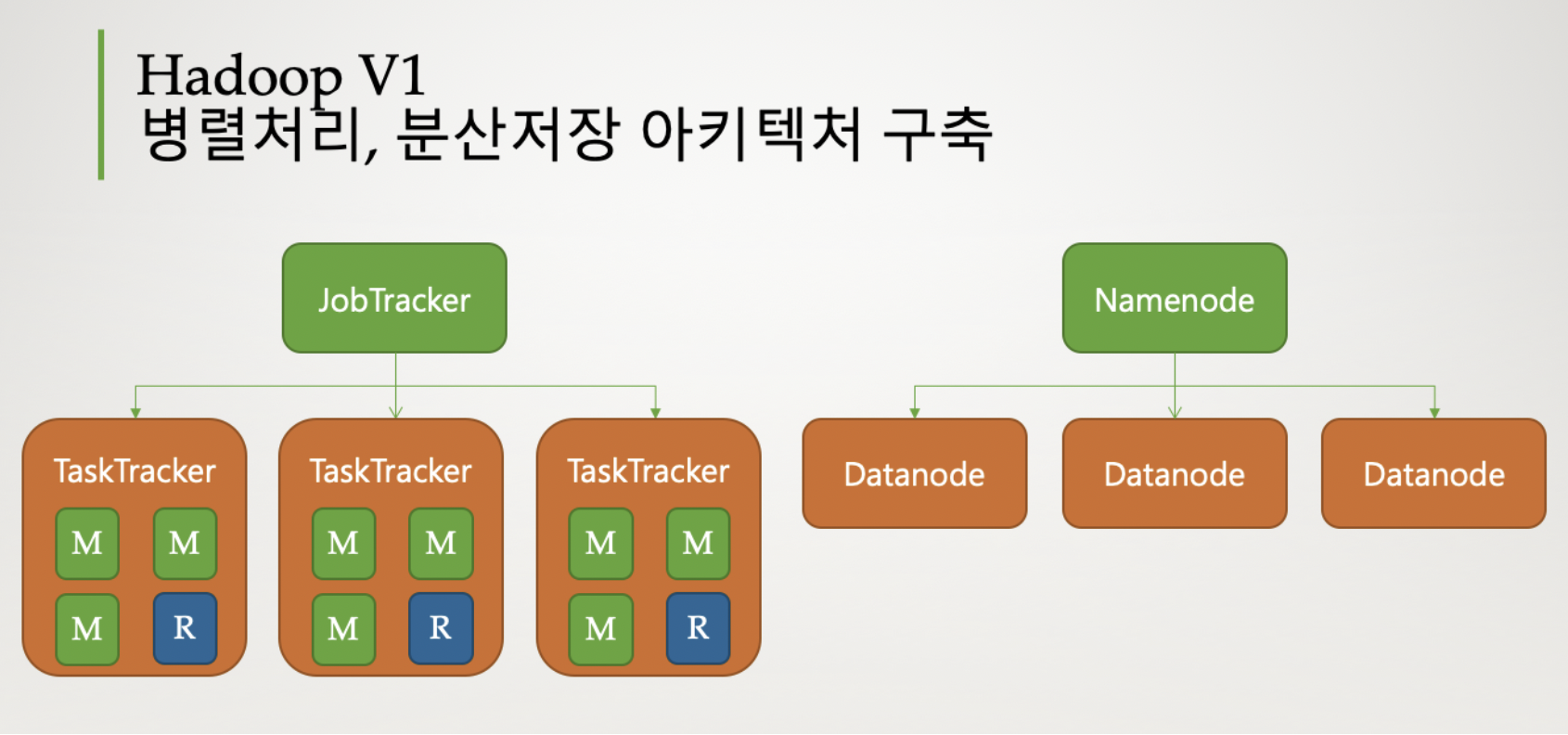
V1: 기본 아키텍처 구성
- MR: Job Tracker & Task Tracker이 담당
- HDFS: Namenode & Datanode가 담당
- Job Tracker가 병렬처리의 클러스터의 자원관리와 애플리케이션의 라이프사이클 관리를 모두하여 병목현상 발생
[HDFS]
- Namenode: 블록정보를 가지고 있는 메타데이터를 관리 & Datanode 관리
- Datanode: 데이터노드에서 데이터를 블록단위로 나누어서 저장
[Map Reduce]
- JobTracker: 전체 작업의 진행상황을 관리하고, 자원 관리도 처리
- TaskTracker: 실제 작업을 처리
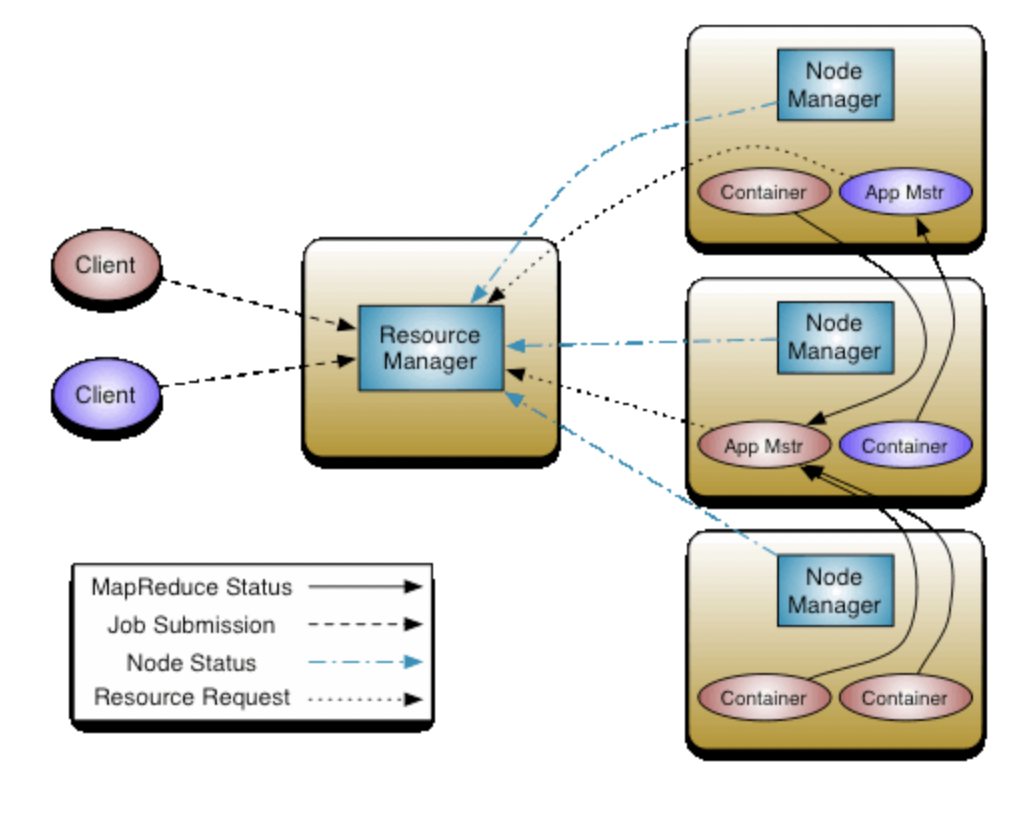
V2: Job Tracker의 병목 현상 해결
- 클러스터의 자원관리: Resource Manager & Node Manager
- 애플리케이션의 라이프 사이클 관리: Application Master & Container
- 작업 처리: Container
[YARN]
- YARN 아키텍처의 작업의 처리 단위는 컨테이너
- 작업에 제출되면 애플리케이션 마스터가 생성되며, 애플리케이션 마스터가 리소스 매니저에 자원을 요청하여 실제 작업을 담당하는 컨테이너를 할당받아 작업을 처리
- 컨테이너는 작업이 요청되면 생성되고, 작업이 완료되면 종료되기 때문에 클러스터를 효율적으로 사용할 수 있음
- MR로 구현된 작업이 아니어도 컨테이너를 할당 받아서 동작할 수 있기 때문에 Spark, HBase, Storm 등 다양한 컴포넌트들을 실행할 수 있음
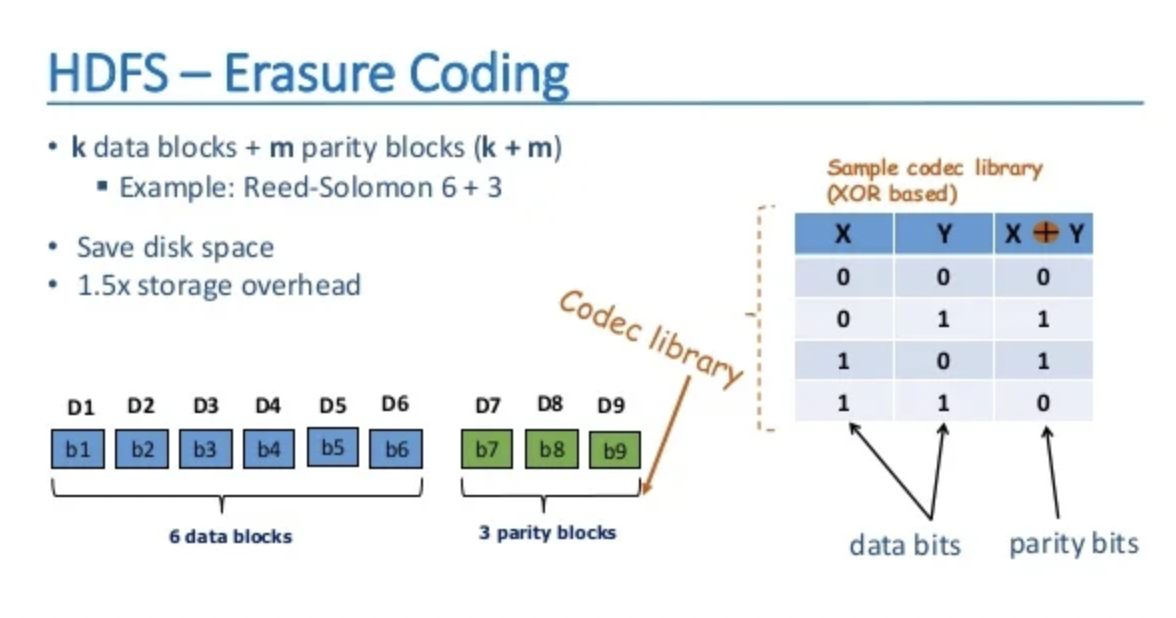
V3
- 이레이져 코딩을 도입하여 HDFS의 데이터 저장 효율성 증가
- YARN 타임라인 서비스를 개선
- 하둡 v1부터 사용하던 쉘스크립트를 다시 작성하여 버그를 해결